
Tech Talk : Comment utiliser l'analyse prédictive pour les campagnes de vente croisée ?
Dans un secteur B2B saturé, la vente croisée est une approche intéressante pour augmenter le chiffre d'affaires à moindre coût. Si un client a déjà acheté vos produits, il est généralement moins coûteux de lui vendre un autre produit que de convaincre un nouvel acheteur.
La plupart des entreprises se sont appuyées sur l'expertise marketing interne pour décider qui contacter dans le cadre d'une campagne de vente croisée. Une autre approche consiste à utiliser des méthodes d'apprentissage automatique pour prendre des décisions étayées par des données afin de déterminer quel client contacter et quel produit proposer.
Dans cet article, nous nous concentrerons sur la construction d'un modèle d'apprentissage automatique pour la vente croisée. Ce modèle permettra de prédire si un client achètera un autre produit de l'entreprise dans un délai défini. L'objectif est d'identifier les caractéristiques des clients qui achètent ce produit et de le recommander à des clients similaires.
Comprendre et transformer les données pour la modélisation
Tout d'abord, nous extrayons les données utiles des systèmes sources. Ensuite, nous les transformons et les rendons disponibles pour la modélisation. Ces étapes sont appelées extraction-transformation-chargement (ETL), dont nous avons parlé précédemment.
Que classons-nous exactement ? Définir une cible précise
Parallèlement à l'ETL, nous devons clarifier la définition de la cible avec le département marketing. La cible est ce que nous allons prédire. Dans notre cas, nous avons défini la cible comme étant l'achat du produit par le client dans les quelques mois suivant une date donnée. Dans cette période future, nous examinons si le client achète ou non, c'est ce que l'on appelle la fenêtre de prédiction.
Sur quelles informations nous appuyons-nous ? S'entretenir avec les parties prenantes
Nous analysons le comportement des clients sur une certaine période de temps dans le passé pour définir leur comportement futur. Nous appelons cette période passée la fenêtre d'observation. Par exemple, le fait de savoir qu'un client a dépensé 1 000 euros il y a cinq ans peut ne pas être pertinent pour notre problème actuel. Le même client qui a dépensé 500 euros pour un autre produit il y a deux mois est probablement plus approprié.

Pouvons-nous prédire si les clients achèteront un produit dans les six prochains mois sur la base de leur comportement au cours des douze derniers mois ?
Nous créons des indicateurs qui décrivent le comportement d'achat du client. Par exemple, on peut étudier le comportement d'achat en fonction de la fenêtre d'observation. Ainsi, nous calculons le montant dépensé par produit, le nombre d'interactions avec l'équipe de vente, le nombre d'échanges avec le service après-vente, le nombre d'emails commerciaux ouverts, etc. Pour calculer ces indicateurs, nous découpons les données pertinentes à partir du système source, puis nous les agrégeons de différentes manières en les additionnant, en prenant la moyenne ou en prenant des ratios. Nous appelons généralement cette partie "ingénierie des caractéristiques".
Encodage des variables catégorielles
Comme nous devons entraîner le modèle de classification avec des données numériques, nous codons les données catégorielles, c'est-à-dire que nous les convertissons en valeurs numériques interprétables par le modèle. La méthode de codage la plus connue consiste à créer une variable binaire par catégorie. C'est ce que nous appelons l'encodage à un coup. Cette méthode est facile à mettre en œuvre et fonctionne généralement bien. Toutefois, lorsque la variable à coder a une cardinalité importante, la création d'une variable binaire par catégorie augmentera considérablement la dimensionnalité de l'ensemble de données. Il peut en résulter un nombre insuffisant d'observations d'entraînement pour prédire la cible. Par exemple, si une variable catégorielle a 250 valeurs uniques, le codage de cette variable créera 250 variables binaires.
Pour encoder ces variables avec une grande cardinalité, l'encodage de la cible est la solution. Pour chaque catégorie, nous calculons la probabilité de la cible. Ensuite, on remplace la catégorie par sa probabilité. On obtient alors une seule colonne contenant les probabilités. Cette méthode fonctionne bien pour des variables telles que les codes postaux ou les codes NACE.
Déséquilibre des classes
Pour certains produits, très peu de clients les utilisaient. Dans nos données d'apprentissage, les deux classes étaient alors complètement déséquilibrées - 5 % de la population appartenait à la classe qui achèterait bientôt le produit, et les 95 % restants ne l'achèteraient pas. Ces proportions sont problématiques car les modèles peuvent classer sans discernement toutes les observations dans la classe majoritaire. Nous avons alors recours à des techniques de suréchantillonnage ou de sous-échantillonnage pour rectifier l'équilibre entre les classes, de 5 %-95 % à 20 %-70 %.
En d'autres termes, nous créons artificiellement de nouvelles observations de la classe minoritaire (suréchantillonnage) ou nous supprimons des observations de la classe majoritaire. Généralement, nous effectuons les deux procédures en parallèle pour atteindre l'équilibre. Dans le cas de cette étude, nous avons combiné le suréchantillonnage avec SMOTE et le sous-échantillonnage aléatoire.
Mesurer la performance d'un modèle dans un contexte marketing
Une fois que vous avez formé des modèles de prédiction, vous voulez évaluer leur utilité. Vous souhaitez également disposer d'une mesure de performance qui aura une signification pour ceux qui l'utiliseront, par exemple l'équipe de marketing. Dans ce contexte, les mesures de qualité sont généralement l'ascension à un certain point ou le gain cumulatif (ascension) à un certain seuil. L'avantage de ces mesures est qu'elles sont directement interprétables.
Ces mesures comparent les performances du modèle à celles d'une sélection aléatoire, répondant ainsi à la question suivante : "Dans quelle mesure mon modèle est-il plus performant que le hasard ? Supposons que nous voulions lancer une campagne de vente croisée et obtenir une liste de clients à contacter.
Il y a plusieurs façons de créer cette liste. Nous pouvons nous fier au hasard, à l'expertise de notre équipe, à un modèle prédictif. Pour chaque méthode, nous demandons que la liste soit triée entre les clients les plus susceptibles d'acheter et ceux qui le sont moins. Si nous décidons de ne contacter que les premiers 10 % de la liste, nous obtiendrons les clients pour lesquels l'équipe marketing ou le modèle prédictif sont les plus confiants. Dans le cas du modèle prédictif, cela se traduira par des scores de prédiction plus élevés.
Un exemple de performance du modèle de vente croisée
Si 20 % de nos clients sont intéressés par l'achat d'un produit, nous voudrons les trouver le plus rapidement possible sans avoir à contacter 100 % de notre base de données. C'est précisément là que l'ascenseur cumulatif est intéressant. Il nous indique la proportion de clients à contacter pour trouver une certaine proportion d'acheteurs.
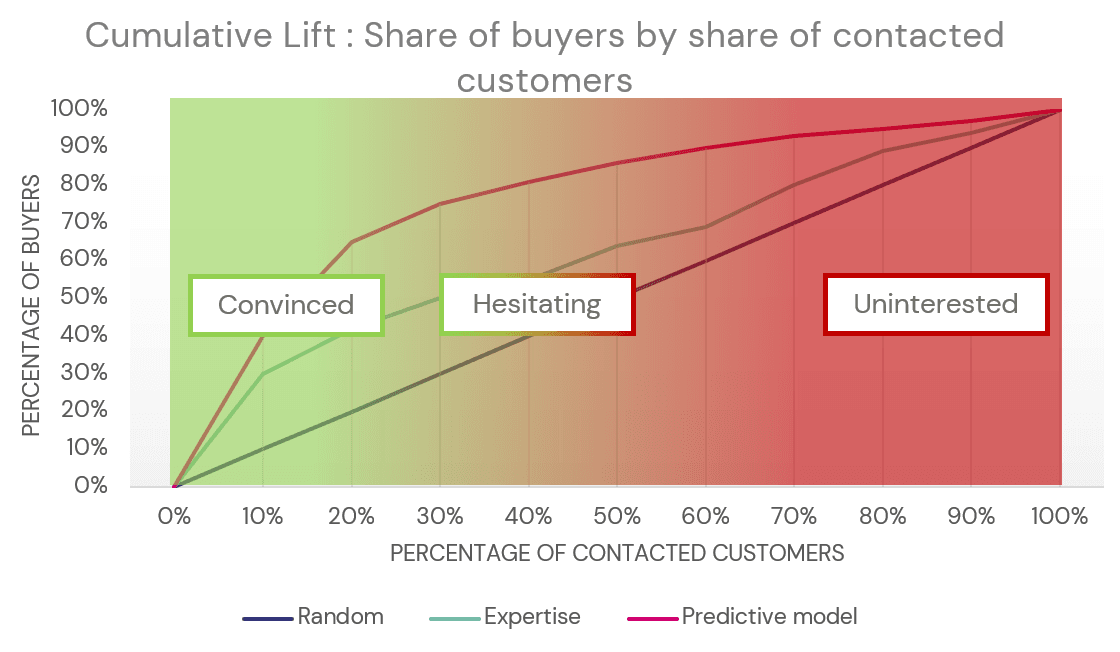
Si nous prenons le graphique ci-dessous, sur l'axe des x, nous avons le pourcentage de clients touchés par la campagne. Il est évident que nous commençons par contacter les clients pour lesquels nous sommes plus sûrs qu'ils achèteront, c'est-à-dire ceux dont les scores de prédiction sont les plus élevés. L'axe des y représente le pourcentage d'acheteurs réels qui ont été contactés. Le graphique comporte plusieurs lignes, en fonction de la méthode utilisée pour créer la liste.

L'effet de levier cumulatif pour un problème de vente croisée comparant la sélection aléatoire, l'expertise et le modèle prédictif
L'utilisation d'une sélection aléatoire de clients permet de trouver des acheteurs de manière linéaire, ce qui signifie que si vous contactez 20 % des clients, vous aurez trouvé 20 % des acheteurs. C'est la performance de base que nous voulons dépasser. Si nous nous appuyons sur une liste d'experts en marketing (ligne turquoise), en contactant les premiers 20 % de clients, nous trouverons environ 40 % de tous les acheteurs, soit deux fois plus que la sélection aléatoire. En contactant les 20 % de clients recommandés par le modèle prédictif (ligne rose/rouge), nous trouverons 60 % de tous les acheteurs.
Il s'agit d'un moyen pratique de décrire les performances du modèle et de les mettre en perspective.
Utiliser les scores de prédiction pour piloter votre stratégie commerciale
Nous pouvons utiliser les mêmes graphiques pour dériver la stratégie de contact. Nous avons déjà pu convaincre les premiers clients dont les scores de prédiction sont les plus élevés. Il n'est donc peut-être pas nécessaire de dépenser de l'argent pour les contacter, car ils achèteront de toute façon le produit. À l'autre extrémité du spectre, les clients des derniers 10 % ne sont généralement pas intéressés par le produit. Contacter ces clients pourrait alors se traduire par un gaspillage d'argent.
Calcul de l'intérêt pour le produit par quantile
C'est à ce stade que la courbe d'ascension cumulative peut orienter la stratégie commerciale. Le graphique ci-dessus attribue les différents quantiles de clients aux segments de ceux qui sont déjà convaincus (scores de prédiction élevés), de ceux qui hésitent (scores de prédiction moyens à élevés) et de ceux qui ne sont pas intéressés (scores de prédiction faibles).
De ces segments, nous pourrions tirer une stratégie :
Soit sécuriser les convaincus
Ou transformer les clients hésitants en clients convaincus
Les enseignements à tirer
Dans ce Tech Talk, nous avons passé en revue différents conseils pour vous aider à créer un modèle prédictif pour les ventes croisées et à élaborer une stratégie commerciale efficace autour des résultats de votre modèle. Nous avons abordé les points suivants :
L'importance de définir précisément la cible avec l'équipe marketing,
Construire vos données de formation sur la base d'une fenêtre d'observation,
Encoder soigneusement vos variables catégorielles,
Adaptez vos données de formation à une classification déséquilibrée,
L'utilisation de l'ascenseur cumulatif pour expliquer la performance de votre modèle,
L'utilisation de l'ascenseur cumulatif pour dériver la stratégie commerciale.