
Tech Talk : L'ETL dans le nuage est-il possible sans codage ? (Partie 1)
Images : https://www.agilytic.be/blog/tech-talk-etl-cloud-coding-part-1
La tendance est à la migration de toutes les solutions de données de l'intérieur vers l'extérieur. L'un des principaux arguments pourrait être la possibilité de réduire le coût total de possession. Dans cette série en trois parties d'exposés techniques sur l'ETL, nous nous concentrons sur les capacités des outils de données fournis par deux acteurs majeurs du cloud : Amazon Web Services (AWS) et Azure.
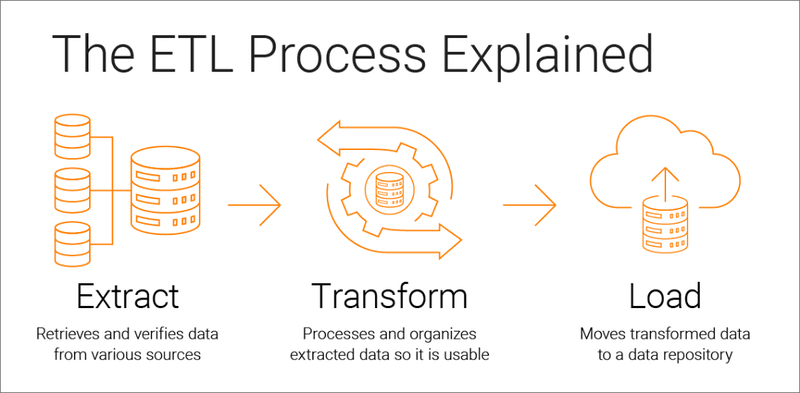
La question fondamentale : qu'est-ce que l'ETL ?
ETL représente un modèle typique de mouvement de données et signifie Extract (à partir d'une source), Transform (les données extraites) et Load (les données transformées, généralement dans une base de données, CSV, feuilles Excel ou un lac de données). En général, les données extraites sont également sauvegardées dans un espace de stockage en nuage (S3 ou blobs). Le nom de ce processus devrait donc être ELT, ou même ELTL, car vous chargez (ou sauvegardez) les données au moins deux fois.
ETL et codage dans le nuage
Si vous êtes ici pour une réponse rapide à la question posée dans le titre : Non, l'ETL dans le nuage n'existe pas sans codage, en dehors de quelques scénarios simples que vous ignorez généralement.
Permettez-moi de développer ce point. En ETL, vous n'extrayez pas deux tables d'une même source, vous les joignez et vous chargez la table résultante dans la base de données de votre fournisseur préféré. Il s'agit plutôt de traiter des dizaines ou des centaines de tables provenant de diverses sources. Ensuite, vous devez créer des champs/colonnes calculés complexes. Enfin, vous devez charger les résultats dans différents modes tels que l'écrasement, l'ajout, etc. Cela signifie qu'il y aura (presque) toujours plus de combinaisons d'opérations que celles prévues par les fournisseurs d'informatique en nuage et fournies dans la boîte.
Scénarios auxquels vous pouvez être confronté : code ou pas code ?
Étant donné que le processus se déroule en trois étapes, il existe trois sources possibles de limitations et plusieurs questions auxquelles il faut répondre :
Extrait. Existe-t-il un connecteur pour cette source de données ? Peut-on extraire en masse ? Analyser non seulement les tables mais aussi les vues et les vues matérialisées ? Sauvegarder les données dans un fichier parquet ?
Transformer. Quels types de transformations et d'agrégations sont nécessaires ? Pouvons-nous facilement déboguer et prévisualiser les données au cours de la phase de développement ?
Chargement. Existe-t-il un connecteur avec le puits de données souhaité ? Quels sont les formats acceptés ? Peut-on charger en masse ? Peut-on choisir le mode de chargement ?
Si la réponse est non à l'une de ces questions, vous devrez personnaliser le processus en écrivant du code. Pour commencer, si vous regardez les outils cloud populaires comme Azure Data Factory et AWS Glue, vous trouverez des modèles de base pour des scénarios simples. En d'autres termes, il existe des outils d'interface utilisateur, mais le codage représente probablement encore 80 % de chaque projet ETL. Les langages de programmation ETL les plus populaires sont Python, Scala et SQL.
ETL Tech Talks up next
Dans les parties 2 et 3, nous décrirons deux cas dans lesquels nous avons utilisé Azure Data Factory et AWS Glue pour aider les clients à établir leurs flux ETL et leurs entrepôts de données.