
Tech Talk : Comment automatiser la détection des erreurs de documents dans les demandes de remboursement ?
Détection des erreurs dans les documents afin de réduire les erreurs et les processus manuels
Si vous demandez à vos clients de remplir un modèle de document, il se peut que les informations fournies par les clients contiennent des erreurs. Cela signifie que vous devez vérifier manuellement s'il y a des erreurs avant de valider le document. Cette méthode de travail est coûteuse et nécessite un grand nombre d'employés pour vérifier chaque document.
Une compagnie d'assurance nous a contactés car elle reçoit chaque année plus de 100.000 factures de ses clients pour un remboursement de frais médicaux. Le projet de détection d'erreurs dans les documents qui suit consiste à classer les factures en deux catégories : 1) le document doit être modifié, ou 2) il ne doit pas l'être. Les données d'entrée comprennent 117 000 factures et 312 caractéristiques. Nous pouvons les décomposer en caractéristiques :
Signalement de la présence d'une ligne de code particulière dans la facture
Montants affichés sur la facture (montant du remboursement, montant supplémentaire, montant total)
Type d'hôpital, chambres et factures
Métadonnées sur le projet de loi (nombre d'entrées et dates)
La plupart des erreurs proviennent de l'utilisation d'un code erroné pour les services reçus par l'hôpital. Ensuite, la date utilisée dans la facture n'est pas la bonne, ou le montant indiqué n'est pas correct non plus.
Prétraitement des données pour la détection des erreurs de documents
Avant d'envoyer les données dans le modèle de détection des erreurs de documents, il est préférable de les prétraiter. Nous pouvons créer de nouvelles variables pour obtenir de meilleures performances, ce que l'on appelle l'ingénierie des caractéristiques. Nous devons classer les variables continues dans des catégories. Nous devons ensuite transformer les variables catégorielles en variables numériques afin que le modèle puisse les traiter.
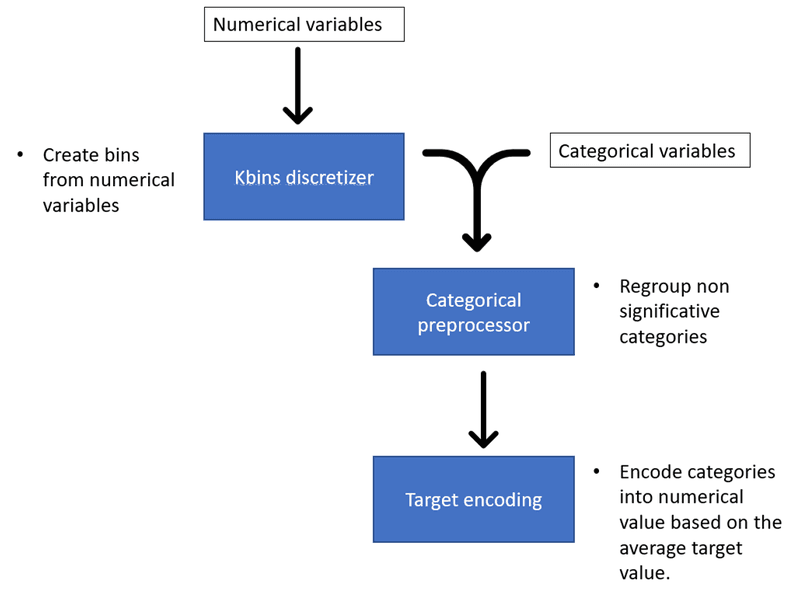
Ingénierie des caractéristiques pour la détection d'erreurs dans les documents
Pour ce faire, nous utilisons la bibliothèque cobra, qui met en œuvre plusieurs fonctions de prétraitement des données. Cobra est pratique car il est possible d'appliquer et d'affiner différentes fonctions de prétraitement en utilisant uniquement un objet de prétraitement.
Ingénierie des fonctionnalités
Nous pouvons essayer d'aider le modèle à découvrir de nouveaux modèles dans les données en créant de nouvelles variables. L'interaction entre différentes variables peut donner naissance à ces variables. Par exemple, nous créons la proportion du montant du remboursement en divisant le montant du remboursement par le montant total.
Nous pouvons également trouver des modèles dans les données en fonction du temps. Ainsi, si vous disposez d'une variable de date, vous pouvez l'utiliser pour créer une variable de mois, de jour de semaine et de saison. Le modèle peut trouver des cycles cachés apparaissant au cours des mois, des jours de la semaine ou des saisons.
Kbins Discretizer
Le discrétiseur Kbins divise les données continues en intervalles d'une taille prédéfinie. Il est intéressant car il peut introduire une non-linéarité dans le modèle. Vous pouvez définir un nombre de bins et la stratégie utilisée pour créer les bins. Il existe trois stratégies dans KBinsDiscretizer :
Uniforme : La largeur des cases est constante dans chaque dimension.
Quantile : chaque case a le même nombre d'échantillons.
Kmeans : La discrétisation est basée sur les centroïdes d'une procédure de regroupement KMeans[1].
Préprocesseur de données catégorielles
Le préprocesseur de données catégoriel implémenté par Cobra va regroupera les catégories de variables catégorielles en fonction de leur importance par rapport à la variable cible. Un test du chi-carré détermine si une catégorie est significativement différente du reste des catégories pour le modèle de classification, compte tenu de la variable cible.
Nous pouvons définir le seuil de la valeur p afin de déterminer à partir de quelle valeur p les catégories sont significatives ou non. Si la catégorie n'est pas significative, elle sera regroupée dans la catégorie "Autres".
Nous pouvons également définir la taille minimale d'une catégorie pour qu'elle reste une catégorie distincte. Elle sera regroupée dans la catégorie "Autres" si la taille de la catégorie est inférieure à cette taille minimale.
Il est également possible de remplacer les valeurs manquantes par la catégorie supplémentaire "Manquant".
Ce module nous permet de ne conserver que les catégories pertinentes et de diminuer le nombre d'échantillons de données isolés dans l'espace dimensionnel.
Codage cible
Le codage cible (ou codage moyen) calcule le rapport des occurrences positives dans la variable cible pour chaque caractéristique. Il s'agit d'un moyen de transformer des valeurs catégorielles en valeurs numériques.

Méthode d'encodage cible pour la détection d'erreurs dans les documents
L'encodage cible est la méthode préférée à l'encodage traditionnel à une touche parce qu'elle n'ajoute pas de colonnes supplémentaires. Le codage à une touche ajouterait de nombreuses dimensions à notre espace dimensionnel qui est déjà composé de 300 caractéristiques. Un espace à haute dimension pose deux problèmes :
Il augmente l'utilisation de la mémoire et du calcul.
Il augmente la capacité du modèle à suradapter les données.
L'encodage des cibles permet donc de réduire l'utilisation de la mémoire et des calculs, ainsi que l'ajustement excessif du modèle.
Cependant, l'encodage cible peut encore introduire un surajustement parce qu'il calcule les ratios sur la base des échantillons d'apprentissage que nous donnons. Les ratios peuvent ne pas être les mêmes dans l'échantillon de test. Par exemple, dans notre échantillon de test, "Petites pièces" peut avoir un ratio de 0,75 au lieu de 0,5. Nous pouvons réduire ce problème en utilisant le lissage additif. Cobra choisit de le mettre en œuvre pour sa classe d'encodage cible. Lorsqu'il calcule le ratio des occurrences positives pour chaque valeur catégorielle, il ajoute le ratio des occurrences positives de la variable cible proportionnellement à un poids. Max Halford l'explique de manière détaillée dans son article.
Modèle et résultats pour la détection d'erreurs dans les documents
En fonction des besoins du client, la mesure appropriée est l'aire sous la courbe (AUC).
Nous sélectionnons les caractéristiques qui augmentent l'AUC de manière substantielle. Pour éviter d'avoir trop de dimensions et réduire la possibilité d'un surajustement, nous n'avons sélectionné que les caractéristiques qui augmentaient l'AUC de manière substantielle. En d'autres termes, nous avons effectué une sélection directe.
Le meilleur modèle est l'arbre de gradient boosting. Nous utilisons la bibliothèque XGBoost, une bibliothèque distribuée optimisée de renforcement du gradient conçue pour être très efficace, flexible et portable. La bibliothèque met en œuvre un arrêt précoce afin d'éviter un surajustement des données d'apprentissage. Il est également possible de spécifier d'autres paramètres, tels que la profondeur maximale de chaque arbre ou la somme minimale des poids d'instance nécessaires pour un enfant. Vous pouvez consulter tous les paramètres disponibles ici.
Nous avons obtenu une AUC de 86,3 %.

Courbe ROC résultant du projet de détection des erreurs dans les documents
Conclusions
Nous avons pu automatiser 47 % des factures avec un taux d'erreur de 3,06 %. Cela signifie qu'environ 55 000 documents n'ont pas eu besoin d'être examinés manuellement, ce qui a permis au client d'économiser un nombre incalculable d'heures.
[1] https://scikitlearn.org/ stable/auto_examples/preprocessing/plot_discretization_strategies.html