
Discussion technique : Des suggestions d'embauche efficaces grâce à un outil de recommandation
Imaginons un marché de l'emploi désireux d'accroître sa compétitivité sur le marché.
L'objectif est de proposer aux utilisateurs des articles qui correspondent à leurs préférences individuelles. La solution doit être construite de manière à ce qu'il soit possible de proposer les articles qui intéresseront le plus les utilisateurs. Cependant, il doit également être possible pour un article de trouver différents utilisateurs susceptibles d'être intéressés par cet article.
Pour ce faire, ils peuvent mettre au point un système de recommandation qu'ils pourront intégrer à leur plateforme. Cet article de Tech Talk explique ce que sont les systèmes de recommandation, les avantages qu'ils présentent pour les entreprises et les différentes approches possibles lors de la mise en œuvre d'un système de recommandation.
Qu'est-ce qu'un système de recommandation ?
Les systèmes de recommandation sont des modèles d'apprentissage automatique intégrés dans les plateformes pour fournir aux utilisateurs des recommandations basées sur l'IA.
Les systèmes de recommandation sont un sujet d'actualité dans le domaine de la science des données, car de nombreuses grandes entreprises comme Netflix, Spotify et Amazon en ont fait un élément central de leur produit. À une époque où les recommandations alimentées par l'IA deviennent monnaie courante, il est important de savoir comment elles peuvent bénéficier à votre entreprise et comment les construire.
Les systèmes de recommandation peuvent être mis en œuvre sur de nombreuses plateformes et dans de nombreux secteurs d'activité. Les avantages qu'ils apportent à une entreprise peuvent varier en fonction de la manière dont ils sont utilisés et des objectifs poursuivis. Voici quelques-uns des avantages qu'ils peuvent apporter à une entreprise :
Fournir un contenu pertinent aux utilisateurs/clients - cela augmente le temps que les gens passent sur votre site web.
Convertir les acheteurs en clients car ils sont plus susceptibles de se voir recommander un produit dont ils ont besoin.
Augmenter les revenus des clients qui achètent plus de produits.
Fidéliser les clients - les clients satisfaits des produits qui leur ont été recommandés sont plus susceptibles de revenir pour d'autres achats.
Nous allons examiner les trois systèmes de recommandation les plus populaires pour vous donner une idée de ce qu'ils sont et de leurs éventuelles lacunes, afin que vous puissiez mieux décider lequel serait le plus avantageux pour votre entreprise. Ces systèmes sont les suivants :
Filtrage basé sur le contenu
Filtrage basé sur la collaboration
Systèmes de recommandation hybrides
Filtrage basé sur le contenu
L'objectif des systèmes de recommandation basés sur le contenu est de faire des recommandations entre un élément et un utilisateur sur la base de la similarité. Les éléments dont les caractéristiques se recoupent le plus avec les préférences et/ou les caractéristiques de l'utilisateur sont recommandés à ce dernier.
Cette méthode ne prend en compte aucune information sur les préférences des autres utilisateurs. Cependant, elle peut intégrer des informations directes et indirectes sur les objets et les utilisateurs afin de mieux déterminer leur similarité.
Les informations dont nous disposons sur les centres d'intérêt de l'utilisateur constituent un élément essentiel d'un système de recommandation basé sur le contenu - l'utilisateur est au centre des préoccupations. Sans ces informations, le modèle ne serait pas en mesure de fournir des recommandations valables.
Habituellement, les utilisateurs doivent remplir un profil lorsqu'ils s'inscrivent pour la première fois sur la plateforme, où ils peuvent préciser certains de leurs centres d'intérêt. Par exemple, Spotify demande aux nouveaux utilisateurs de choisir leurs artistes et genres musicaux préférés, ce qui permet ensuite de fournir des recommandations sur des genres ou des artistes similaires.
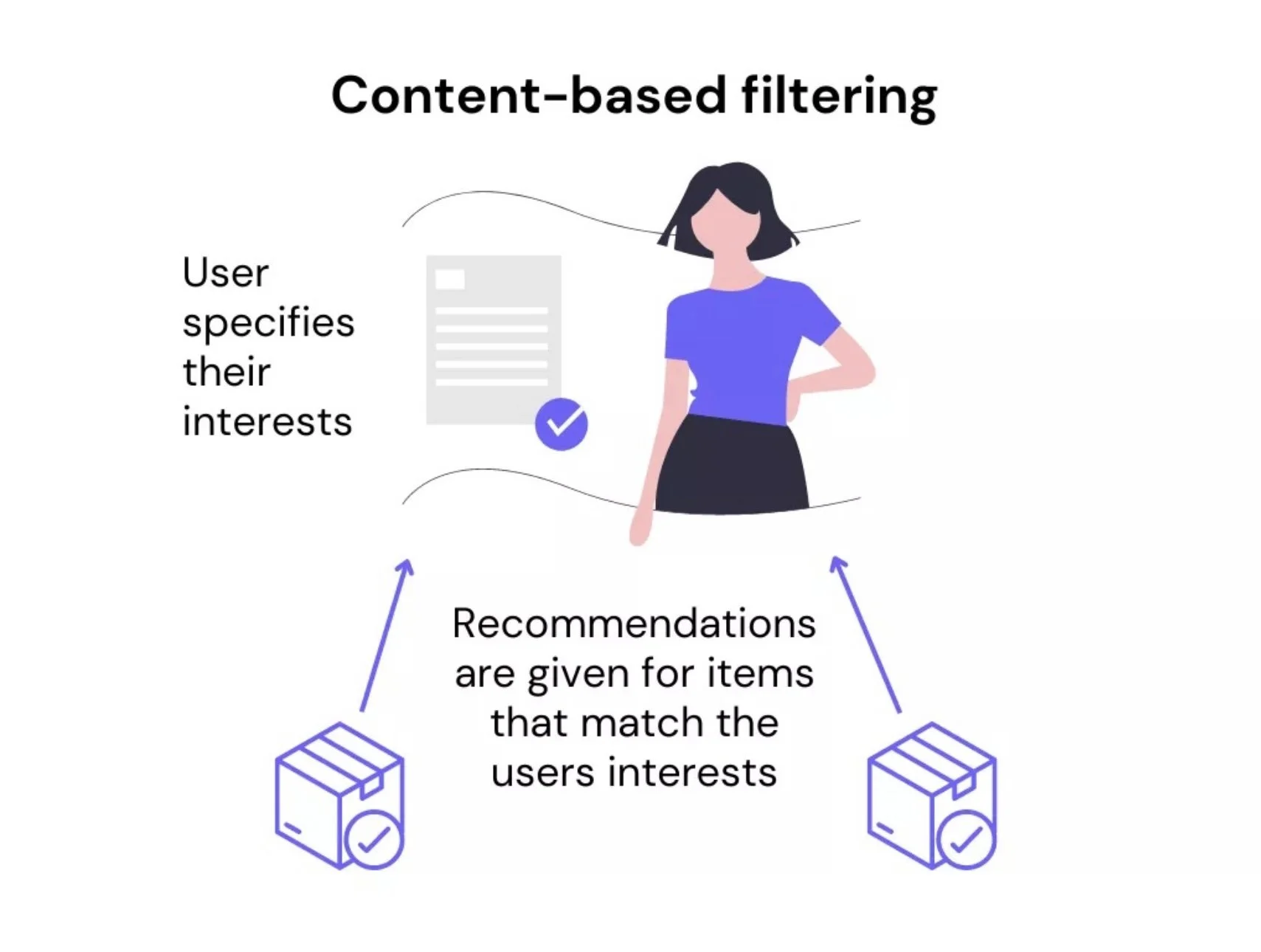
Le filtrage basé sur le contenu peut aider à surmonter le "problème du démarrage à froid" lorsque nous ne disposons pas de suffisamment de données historiques sur les interactions de l'utilisateur sur les plateformes. Toutefois, les recommandations sont spécifiques à l'utilisateur et portent sur un très petit sous-ensemble d'articles susceptibles d'être proposés.
Plusieurs mesures peuvent être utilisées pour calculer la similarité entre les utilisateurs et les objets, comme par exemple :
Distance euclidienne
Distance de Manhattan
Distance de Jaccard
Distance cosinusoïdale/similarité
L'une des mesures les plus populaires de cette liste est la similarité en cosinus. Cette méthode calcule la similarité entre deux vecteurs (l'utilisateur et l'article, par exemple) en utilisant le cosinus de l'angle qui les sépare. Cela signifie que les angles les plus faibles entre deux vecteurs ont des valeurs de cosinus plus élevées et qu'ils sont donc très similaires l'un à l'autre.
Filtrage basé sur la collaboration
Le filtrage basé sur la collaboration permet de surmonter certaines des lacunes du filtrage basé sur le contenu. Si nous disposons d'informations sur les interactions antérieures entre les éléments et les utilisateurs, elles peuvent être utilisées pour construire un système de recommandation qui fournit une plus grande variété de recommandations.
Par exemple, si l'utilisateur A achète un produit et que l'utilisateur A est similaire à l'utilisateur B, ce produit sera recommandé à l'utilisateur B.

Les utilisateurs similaires sont regroupés et le modèle tient compte de leurs interactions avec les articles pour faire des recommandations aux autres utilisateurs. Les utilisateurs peuvent explicitement noter un article pour indiquer s'ils l'ont aimé ou non, ou le système peut déduire cette information en se basant uniquement sur l'interaction des utilisateurs avec l'article - s'ils cliquent dessus ou l'ajoutent à leur panier, par exemple.
Cependant, un inconvénient important de cette approche est qu'elle a besoin d'informations sur ces interactions antérieures, et qu'elle en a besoin d'un grand nombre. En d'autres termes, elle nécessite un "démarrage à chaud". Ce type de données n'est pas toujours disponible, en particulier pour les plates-formes plus jeunes qui ne disposent pas d'une large base d'utilisateurs ou de nombreuses interactions antérieures. En outre, si de nouveaux articles sont ajoutés à la plateforme, ils ne seront pas recommandés par le système tant que les utilisateurs n'auront pas interagi avec eux ou ne les auront pas évalués.
Il existe deux méthodes pour construire des modèles de filtrage collaboratif : la méthode basée sur la mémoire et la méthode basée sur le modèle.
Les méthodes basées sur la mémoire calculent la métrique de similarité et font ensuite des recommandations basées sur un algorithme tel que les voisins les plus proches.
Les méthodes fondées sur un modèle utilisent des algorithmes de réduction de la dimensionnalité pour comprimer la matrice utilisateur-élément. Cette méthode est particulièrement utile lorsque la matrice est peu dense - en d'autres termes, les utilisateurs n'attribuent une note qu'à un petit nombre d'éléments, de sorte que la plupart des entrées de cette matrice sont vides. Une approche courante consiste à utiliser l'algorithme de décomposition en valeurs singulières (SVD).
Systèmes de recommandation hybrides
Cette approche combine le filtrage basé sur le contenu et le filtrage basé sur la collaboration en un seul système de recommandation. De cette manière, nous pouvons combiner le meilleur des deux mondes et obtenir de meilleures recommandations en surmontant les lacunes de chaque approche.
Nous pouvons construire un modèle hybride en créant séparément des systèmes basés sur le contenu et des systèmes basés sur la collaboration. Ensuite, nous pouvons combiner chacun de leurs scores à l'aide d'une combinaison linéaire avec des poids que nous pouvons spécifier.
Par exemple, s'il n'y a pas assez de données sur les interactions antérieures des utilisateurs, nous pouvons donner plus de poids au système basé sur le contenu. Lorsque nous disposerons de plus de données à l'avenir, nous pourrons ajuster ces pondérations.
Remarques finales
Cet article a présenté les types de systèmes de recommandation qui sont devenus si populaires ces dernières années. Bien que le filtrage basé sur le contenu et le filtrage collaboratif présentent certains inconvénients, ils peuvent être incorporés dans un système hybride qui offre une approche puissante pour fournir des recommandations alimentées par l'IA dans votre plateforme.
Il y a deux derniers points que vous devez prendre en considération lorsque vous construisez ces systèmes :
Les systèmes de recommandation doivent être recyclés régulièrement pour rester pertinents. La fréquence de ce recyclage dépend de la croissance de votre plateforme et de la quantité de nouvelles données qu'elle reçoit.
La vitesse et la performance de l'algorithme sont très importantes lors de son intégration dans votre plateforme. L'optimisation du code et de l'infrastructure utilisée pour ce système est une étape cruciale qui doit être prise en compte avant et pendant le projet.
Pour en savoir plus sur les systèmes de recommandation, Google propose un cours gratuit qui couvre très bien le sujet. En outre, la conférence RecSys 2022 présente les dernières recherches et les nouvelles méthodes de construction des systèmes de recommandation (pour une version résumée de la conférence, Eugene Yan a écrit un excellent résumé de quelques-uns des documents présentés).