
Discussion technique : Classification et prédiction de documents à l'aide d'une application intégrée (Partie 2)
Cet article est la suite d'une série en deux parties. Pour l'instant, nous allons discuter de notre flux de travail pour notre projet de classification de documents. Tout d'abord, la page d'accueil de l'application s'affiche automatiquement lorsque l'utilisateur exécute le fichier main.py.
Comme l'illustre la figure 1, nous proposons deux options. Soit l'utilisateur peut exécuter l'ensemble du processus à partir de modèles de formation pour prédire les nouveaux documents à venir. Soit l'utilisateur peut uniquement utiliser la prédiction de documents (basée sur la spécification d'un modèle précédemment entraîné).
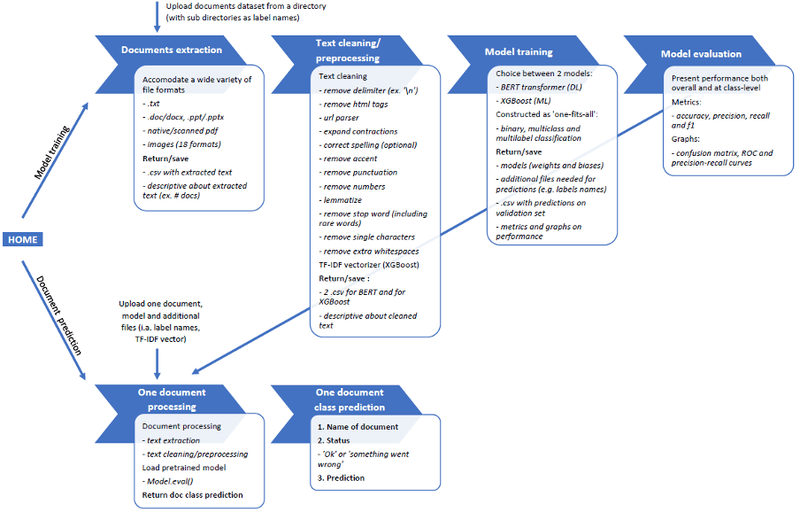
Figure 1. Flux de travail global de l'application de classification et de prédiction de documents
Programmation Python pour la classification des documents
1. API RESTful Flask
Nous avons créé deux API pour ce projet, fonctionnant simultanément et à des fins différentes.
L'API principale agit comme un cadre central. Elle coordonne l'ensemble du processus et du flux de travail et permet une communication fluide entre l'interface utilisateur et les objets python.
L'API secondaire se trouve dans le fichier main.py. Elle récupère les variables envoyées au système lorsque des requêtes asynchrones sont exécutées pendant la navigation dans l'application (JavaScript). Nous ne pourrions pas récupérer ces informations autrement.
2. Objets Python
Au total, le projet compte une dizaine d'objets de classe python dont nous présentons ici les plus importants.
L'objet de classe "Extracteur" de ce fichier peut prendre en charge un grand nombre de formats de fichiers. Cela inclut les fichiers de documents natifs ainsi que les formats de documents ou d'images numérisés. Les formats de fichiers pris en charge sont les suivants :
formats de fichiers de documents : .txt, .pdf, .doc/.docx, .ppt/.pptx
format de fichier image/document numérisé : pdfs numérisés, .bmp, .dib, .jpeg, .jpg, .jpe, .jp2, .png, .pbm, .pgm, .ppm, .pxm, .pnm, .pfm, .sr, .ras, .exr, .hdr, .pi
L'extracteur de documents s'appuie, entre autres, sur les bibliothèques suivantes : win32com, docx, pptx, pytesseract (OCR), pdfminer, pdf2image ;
L'objet de classe 'TextCleaner' de ce fichier utilise les méthodes de nettoyage de texte NLP suivantes : suppression du délimiteur (par exemple '\n'), suppression des balises HTML, analyse de l'URL (en ne conservant que le nom de domaine comme, par exemple, 'cosmetic' pour www.cosmetic.be), expansion de la contraction, correction de l'orthographe (facultatif), suppression de l'accent, suppression de la ponctuation, suppression des nombres, lemmatisation, suppression des mots vides, suppression du caractère unique et suppression de l'espace blanc supplémentaire.
Le traitement de l'orthographe correcte est facultatif ; l'utilisateur peut l'utiliser ou non. Par exemple, lors de la navigation dans l'interface de l'application, voir la section suivante. Nous recommandons d'utiliser cette option uniquement lorsque le texte peut être de faible qualité. Nous entendons par là les contenus des médias sociaux avec leur langage "jargonneux" et les scans et/ou images de faible qualité où l'OCR risque de produire des erreurs. Pour les textes réputés de bonne qualité (par exemple, les articles scientifiques ou les résumés), il est préférable de ne pas utiliser cette option. Nous avons remarqué que la bibliothèque de correction orthographique remplace parfois des mots corrects par d'autres mots similaires, par exemple "physique" pour "topologique".
La fonction "supprimer les mots vides" est basée sur une liste de mots vides construite au cours du processus. Cette liste est en partie basée sur la liste existante de mots vides fournie par certaines bibliothèques NLP (y compris sklearn, spacy, gensim et nltk). Cette liste est également basée sur le corpus lui-même, puisqu'elle inclut tous les mots qui n'apparaissent que dans un seul document. L'inclusion des mots "rares" se justifie par le fait qu'ils n'opèrent aucune discrimination entre les classes et peuvent être considérés comme du bruit.
Outre le nettoyage du texte, TextCleaner produit également le vecteur TF-IDF nécessaire à l'exécution du modèle XGBoost.
Les deux modèles dont nous avons parlé précédemment sont matérialisés par deux autres objets de classe qui ont la même structure :
Séparation de la formation et de la validation stratifiées
Modèle de formation
Évaluation du modèle sur l'ensemble de validation (30% de l'échantillon total)
Nous devions prendre en compte les types d'ensembles de données multi-classes et multi-labels pendant la formation. C'est pourquoi nous avons choisi d'opérer une division stratifiée de la formation-validation au lieu de la division plus conventionnelle de la formation-validation.
Lorsqu'il est confronté à un ensemble de données multi-labels au cours de la formation, le modèle prend en compte le nombre de classes d'origine et toutes les combinaisons de classes présentées. Ainsi, le nombre de combinaisons de classes potentielles est beaucoup plus important que le nombre de classes d'origine. Certaines combinaisons de classes peuvent comporter très peu de documents, voire aucun document.
La figure 2 présente le nombre de valeurs de chaque combinaison de classe spécifique (codée à chaud pour les combinaisons multiclasses) pour un ensemble de données donné. Comme indiqué précédemment, certaines combinaisons de classes n'apparaissent pas dans le décompte (par exemple [1 0 1 1 1 1]) car elles n'ont aucun document, et d'autres ont très peu de documents (par exemple, la combinaison de classes [0 0 1 1 0 1] n'a qu'un seul document).

Figure 2. Nombre de valeurs des combinaisons de classes pour un ensemble de données multi-labels
Dans un tel contexte, le risque d'un partage conventionnel de la validation de la formation est que certaines combinaisons de classes que le modèle n'a pas vues auparavant au cours de la formation soient présentées lors de son évaluation. À cet égard, la répartition stratifiée de la validation de la formation garantit que la proportion de la répartition de la validation de la formation (dans notre cas, 70 % contre 30 %) est respectée d'une manière ou d'une autre dans chaque combinaison de classes et qu'aucune combinaison de classes non vue n'est présentée lors de l'évaluation du modèle.
L'objet de classe "Rapport" offre une analyse détaillée et approfondie du modèle, tant au niveau global qu'au niveau de la classe, y compris, entre autres, des rapports de classification, des matrices de confusion, des courbes ROC et des courbes de précision-rappel. La figure 3 présente quelques exemples de résultats de ce rapport.
Lorsque l'utilisateur est satisfait des performances d'un modèle, l'objet "Prédiction" peut prédire la classe d'un document entrant non étiqueté. Avant d'exécuter son code, cet objet appelle les objets "Extractor" et "Cleaner" pour prétraiter le texte des documents de la même manière que lors de l'apprentissage.

Figure 3. Exemples de résultats du rapport de performance


Navigation dans l'interface utilisateur de l'application pour la classification des documents
Pour l'affichage des fichiers HTML conçus pour l'interface utilisateur, le projet actuel s'appuie sur un wrapper d'interface utilisateur graphique (GUI) spécifique à Python (le paquet pywebview ) car il permet certaines fonctionnalités spécifiques nécessaires à l'exécution du code et qui ne seraient pas permises avec les GUI basées sur le web plus couramment utilisées (par exemple, Google Chrome). Au cours du processus, le système a dû récupérer le chemin complet de certains fichiers ou répertoires, par exemple pour traiter l'ensemble de données des documents. Bien que cela soit parfaitement possible avec pywebview, Chrome téléchargeait le fichier et récupérait le nom du fichier (sans le chemin d'accès) dans des cas similaires.
Nous avons conçu l'interface utilisateur de manière à ce qu'elle soit explicite et intuitive. En outre, nous avons essayé de donner à l'utilisateur le contrôle de chaque étape du processus et de lui offrir une bonne visibilité sur le déroulement des opérations (rapports intermédiaires fournis après chaque étape et avant le lancement de l'étape suivante). L'objectif était d'aider l'utilisateur à avoir un bon aperçu des données, du traitement des données et de la qualité du modèle. La figure 4 montre la page d'accueil de l'interface utilisateur de l'application.

Figure 4. Page d'accueil de l'interface utilisateur de l'application
L'application web de prédiction de documents
Comme indiqué précédemment, l'application web ne couvre que le flux de travail de prédiction des documents (et non le flux de travail d'apprentissage des modèles). En ce sens, elle utilise le même code python que l'ensemble du projet (mais seulement les classes et les fonctions utilisées pour la prédiction), mais certains changements doivent être apportés en ce qui concerne l'interface utilisateur et le déploiement.
Lorsque l'utilisateur télécharge un document, la prédiction est automatiquement traitée et l'utilisateur est ensuite redirigé vers la page du rapport de prédiction, qui comprend le résultat suivant :
Le nom du document
Statut : "ok" ou "ko" (ce qui signifie que quelque chose n'a pas fonctionné : le format de fichier n'est pas pris en charge ou le document est ouvert dans un autre système/logiciel).
Classe prévue
Un autre avantage par rapport à l'application locale est que les fichiers HTML ont dû être extraits de pywebview pour être rendus dans n'importe quel navigateur web / interface utilisateur (voir figure 5).

Figure 5. Page d'accueil de l'application web
L'application web a été déployée sur Microsoft Azure pour tester son bon fonctionnement. Nous avons utilisé Docker pour créer l'environnement de développement. Pour utiliser Docker, deux fichiers ont été créés :
Le 'Dockerfile' nous permet de créer une image Docker du projet avec toutes les conditions requises pour l'exécuter (y compris tous les paquets python utilisés par le système).
Le fichier "docker-compose.yml" donne toutes les instructions nécessaires à l'environnement d'hébergement pour lancer l'application et la faire fonctionner.
Travis CI est un service d'intégration continue hébergé utilisé pour construire et tester des projets logiciels hébergés sur GitHub. En complément de Docker, nous avons également utilisé Travis CI pour créer un pipeline de connexion directe entre le référentiel local (cloné à partir du référentiel actuel) et l'application web déployée sur Azure. Dans l'intérêt de ce projet, il est plus facile de mettre à jour le système avec des modèles nouvellement formés.
Conclusion et développements futurs possibles pour la classification des documents
Dans l'ensemble, le projet actuel a atteint un point où il est performant et hautement fonctionnel (qu'il soit utilisé par des utilisateurs inexpérimentés ou par des utilisateurs experts). Tant que nous présentons correctement les données au système (le répertoire contenant les documents de l'ensemble de données avec les sous-répertoires comme noms d'étiquettes), l'application peut s'adapter à différents formats de fichiers et types d'ensembles de données (pour la classification de documents binaires, multiclasses ou multiétiquettes).
En ce sens, ce projet offre des outils très polyvalents que nous pouvons adapter à divers cas d'entreprise. Enfin, les applications commerciales du type du projet actuel sont également virtuellement infinies. Pour ne citer que quelques exemples :
Automatiser l'envoi des documents de l'entreprise (à la bonne personne ou au bon service) ;
Automatiser l'envoi et le tri des courriels
Améliorer les performances des moteurs de recherche de documents et de contenus textuels
Détecter les spams ou les documents frauduleux/atypiques
Traiter le texte des dossiers médicaux pour détecter les pathologies et les comorbidités (situation de type "multilabel"). Un tel système devrait toutefois intégrer des données médicales supplémentaires provenant des patients, telles que des images médicales ou des résultats d'examens.