
L'apprentissage automatique causal au service de la prise de décision
Dans le monde de l'apprentissage automatique, des prévisions précises constituent souvent l'épine dorsale de la prise de décision. Toutefois, dans un environnement où le contexte et les actions évoluent constamment, la robustesse des modèles prédictifs peut être compromise au fil du temps.
Pour une stratégie plus complète, il est conseillé d'explorer le domaine du Causal Machine Learning. Cette approche de pointe nous permet de dévoiler les relations de cause à effet et d'obtenir des résultats précis pour anticiper le résultat d'actions spécifiques.
Comprendre l'apprentissage automatique causal
L'apprentissage automatique traditionnel se concentre principalement sur l'identification de corrélations et sur l'élaboration de prédictions basées sur ces corrélations.
L'apprentissage automatique causal va plus loin en s'efforçant de comprendre les liens de cause à effet entre les variables. Dans l'apprentissage automatique causal, l'objectif n'est pas seulement de déterminer les caractéristiques qui contribuent à prédire un résultat, mais aussi de découvrir les facteurs de causalité qui induisent le résultat et de quantifier avec précision leur impact.
-
Prenons, par exemple, la tâche de prédire le taux de désaffection des clients. Supposons que nous travaillions pour un opérateur de télécommunications pour lequel nous créons un ensemble de données complet qui nous permettra de prédire avec précision le désengagement de chaque client.
Après la formation d'un modèle ML et la réalisation de tests rigoureux, il est apparu que le prix de l'abonnement était la caractéristique la plus influente. Après avoir présenté nos résultats, les parties prenantes ont pris la décision logique d'accorder une réduction aux clients identifiés comme étant "à risque". Ce faisant, ils ont pu conserver la plupart des clients.
Plus tard, lorsque le modèle sera à nouveau sollicité pour prédire les niveaux de désabonnement, le client recevra un résultat indiquant qu'il n'y a actuellement aucun client à risque. Ce résultat n'est pas très logique d'un point de vue commercial.
En accordant une remise pour fidéliser les clients, l'opérateur a perturbé la relation entre le prix et la perte de clientèle, en fournissant une raison convaincante à sa décision.
-
Le concept à garder à l'esprit lors de l'élaboration d'un modèle de prédiction est que la caractéristique ayant le score d'importance le plus élevé :
Ce n'est peut-être pas la meilleure caractéristique sur laquelle agir (et si la meilleure caractéristique était l'âge du client ?)
Il se peut même que cela n'ait aucune incidence sur le résultat.
Cette dernière remarque peut surprendre. Cependant, il est bien connu que les modèles de corrélation peuvent être fallacieux.

Se concentrer uniquement sur les prédictions est acceptable, mais cela devient problématique lorsque des décisions sont prises sur la base de ces prédictions, en particulier lorsque ces décisions peuvent directement affecter l'état actuel de l'environnement. Le ML causal déplace son attention des simples modèles prédictifs qui dépendent des corrélations vers des modèles qui peuvent alimenter la machinerie de la cause et de l'effet.

Source : XKCD
Se tourner vers l'apprentissage automatique des causes
C'est le moment idéal pour donner une définition précise de l'apprentissage automatique causal. L'apprentissage automatique causal représente un changement d'orientation du point de vue de la modélisation :
Au lieu de faire des prédictions, nous nous efforçons d'identifier les variables responsables du résultat.
Estimez comment ce résultat changerait si nous modifiions ces variables.
Ou, de manière plus formelle : Un traitement T provoque un résultat Y si et seulement si le changement de T entraîne un changement de Y alors que tout le reste reste reste constant.
Si l'on considère ce changement d'un point de vue commercial, l'évaluation consiste essentiellement à répondre à la question "et si...". Que se passerait-il si je ne changeais pas le prix que j'offre au client ? Combien de clients se seraient désabonnés ? C'est ce que l'on appelle communément un contrefactuel. Imaginez qu'il s'agit d'une dimension parallèle, où tout reste inchangé, à l'exception de la manière dont les choses sont gérées.
La simulation d'un univers parallèle est indéniablement un défi, tout comme la prédiction du contrefactuel. Nous n'observons jamais cet univers, et il peut exister diverses structures causales susceptibles de répondre à votre problème. Cela signifie qu'il y a plusieurs traitements à prendre en considération. Alors, comment faire ?
Application du ML causal
L'apprentissage automatique causal se distingue lorsqu'il est associé à une compréhension approfondie de l'activité et à des bases solides en matière de raisonnement logique.
La première étape est la modélisation, dans laquelle nous construisons un graphique de causalité englobant le traitement, le résultat et les variables confusionnelles potentielles. C'est à ce stade qu'il convient d'impliquer le plus possible les parties prenantes de l'entreprise, car leurs points de vue seront extrêmement précieux. Par exemple, pour l'exemple du taux de désabonnement ci-dessus, le graphe acyclique direct pourrait ressembler à ceci :
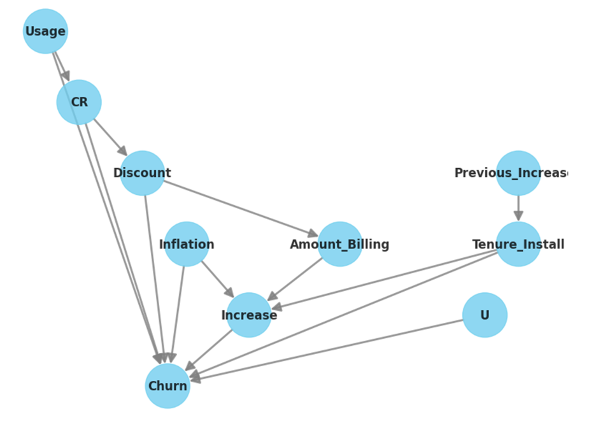
L'étape cruciale suivante est l'identification, qui consiste à choisir avec soin l'algorithme qui répondra efficacement à votre scénario spécifique. Cela peut impliquer une série d'options, telles que des expériences randomisées, un examen approfondi de tous les facteurs de confusion ou la réalisation de tests A/B rigoureux. Causal ML de Microsoft propose un arbre de décision pour vous aider à choisir la bibliothèque adaptée à votre contexte.
Après la modélisation et l'identification, la troisième étape consiste à effectuer l'estimation en utilisant l'algorithme sélectionné sur votre ensemble de données.
L'étape finale est la réfutation, qui consiste à tester la validité du modèle. Il peut s'agir d'un test placebo, où le traitement est remplacé par une valeur aléatoire pour voir s'il y a un effet sur le résultat.
La question épineuse des tests A/B
Les expériences menées par l'équipe de Microsoft illustrent la pléthore d'applications de l'apprentissage automatique causal. Elles comprennent des scénarios tels que l'étude des annulations de réservations d'hôtel, l'analyse de l'efficacité des programmes de fidélisation des clients ou même la prédiction de l'attrition de la clientèle.
À ce stade de l'article, les lecteurs pourraient se demander : "Nous mettons déjà en œuvre l'apprentissage automatique causal. J'ai effectué des tests A/B récemment.
Bien que les tests A/B soient un élément important de la ML causale, ils doivent être abordés avec beaucoup de précautions, en particulier dans un contexte commercial.
Le succès des tests A/B repose en grande partie sur des hypothèses essentielles, dont l'une est de ne réaliser qu'une seule expérience à la fois. En outre, les tests A/B ne vous permettent pas de discriminer a priori vos clients.
Prenons un nouvel exemple. Imaginez que vous possédiez deux restaurants sushis. Ces restaurants sont similaires à tous points de vue. Taille, nourriture, prix, segmentation de la clientèle...
Un jour, lassé des sushis, vous avez envie d'une nouvelle aventure culinaire. C'est alors que vous faites le choix audacieux d'introduire un plat entièrement nouveau et alléchant.
Cependant, vous êtes tiraillé entre les choix de salades et de pâtes.
Vous décidez d'effectuer un test A/B et de ne servir que des salades dans le restaurant 1 et des pâtes dans le restaurant 2.
Après avoir analysé les données relatives aux recettes pendant un mois, il apparaît clairement que les pâtes sont sans aucun doute l'option la plus rentable ! Nos deux restaurants sont spécialisés dans le service d'une grande variété de délicieux plats de pâtes. Il se peut que cette option ne réponde pas aux attentes de tous vos clients.
Cible: Ces clients dévorent volontiers des assiettes de spaghettis, mais quittent rapidement tout restaurant qui ne sert que des salades.
Une certitude: quoi que vous cuisiniez, ces clients viendront dans votre restaurant.
Les causes perdues: Peu importe ce que vous proposez sur le menu, ces clients ne dîneront jamais dans votre restaurant.
Sleepy Dogs: Si vous arrêtez de servir des sushis, ces clients partiront.

Dans un monde parfait, vous pourriez vous concentrer exclusivement sur vos clients cibles.
Malheureusement, personne ne peut être à la fois traité et non traité. Un seul de ces résultats potentiels peut être observé. Celui qui n'est pas observé est un contrefactuel. L'absence d'inférence causale peut conduire à une perte inattendue de clients, qui pourrait dépasser vos attentes.
L'importance de l'apprentissage automatique causal
L'apprentissage automatique causal fournit des informations qui ne peuvent pas être tirées de simples prédictions. En étant consciente des relations de cause à effet, une entreprise peut prendre des décisions mieux informées et, par conséquent, créer des stratégies solides qui restent pertinentes malgré l'évolution rapide de l'environnement.
Si le processus peut sembler exigeant, les récompenses sont à la hauteur, allant du prix Nobel pour les chercheurs aux avantages pratiques pour les entreprises. Une fois que l'on a pris le coup de main, l'apprentissage automatique causal a le potentiel d'ouvrir une ère de prise de décision améliorée, alimentée par des informations éclairées.