
Discussion technique : Recherche dans un grand champ de texte avec Elasticsearch et Kibana (Partie 2)
Dans la partie 1 de cette série d'articles, nous avons présenté les champs stockés et comment modifier la configuration par défaut dans Elasticsearch. D'après notre jeu de données, la modification de la configuration par défaut n'a pas amélioré les performances. Ici, nous allons discuter de la fonctionnalité de mise en évidence d'Elasticsearch , de sa configuration et de l'amélioration potentielle des performances que nous pouvons obtenir.
Il est souvent utile de savoir quel mot ou token des documents correspond à notre requête. Dans Elasticsearch, la fonction de mise en évidence du mot s'appelle, vous l'aurez deviné, la mise en évidence. Cette fonctionnalité peut être gourmande en ressources CPU et en temps dans certains cas. L'un de ces cas est la mise en évidence à partir d'un grand champ de texte. Nous verrons les différentes méthodes de mise en évidence sans entrer dans les détails techniques. Nous comparerons ensuite les performances des méthodes en fonction de nos cas d'utilisation et de notre ensemble de données.
Pour rappel, notre jeu de données est composé de documents JSON contenant des méta-données telles que "titre" et "auteur". Un champ supplémentaire contient le texte extrait du PDF. Ce champ a une taille moyenne de 200K caractères (200 KB).
Mise en évidence avec Elasticsearch
Nous avons besoin de savoir si nous pouvons optimiser le processus de mise en évidence dans Elasticsearch sur notre jeu de données. D'après la documentation officielle, nous pouvons paramétrer la façon dont nous voulons mettre en évidence nos résultats de recherche. Nous allons essayer d'optimiser nos performances de mise en évidence en fonction de deux paramètres différents :
1. Stratégie de décalage : Postings : il ajoutera un emplacement de décalage pour chaque terme dans l'index inversé. De cette manière, Elasticsearch sera en mesure de connaître rapidement l'emplacement d'un terme spécifique sans analyse.
Term vector with_positions_offsets: Une structure de données supplémentaire offrant des fonctionnalités avancées pour la notation des résultats. Selon la documentation officielle, elle est censée être la plus efficace pour un vaste champ (> 1 mb). Elle est également susceptible de consommer beaucoup plus d'espace disque.
Note : la configuration par défaut d'Elasticsearch est d'indexer les documents sans calculer d'offset.
2. Surligneur : Unified : avec l'algorithme BM25 pour noter les résultats. C'est le surligneur par défaut.
FVH (Fact vector highlighter) : avec l'algorithme tf-idf, il nécessite l'utilisation d'un vecteur de termes avec_positions_offsets.
Plain : Il reconstruit un minuscule index complet en mémoire au moment de la requête pour chaque document et chaque champ.
Par défaut, Elasticsearch ne construit ni les affichages ni les vecteurs de termes. Cela signifie que la fonction de surlignage utilisera le surligneur unifié sans stratégie de décalage.
Lors du choix d'un surligneur particulier, certaines fonctionnalités ne seront plus accessibles. Nous vous recommandons de lire la documentation officielle.
Mesure des performances avec Elasticsearch
Nous avons décidé de mesurer les performances de différentes configurations de mise en évidence. Ces mesures visent à obtenir une estimation approximative de la meilleure configuration à choisir dans le cadre d'une démonstration de faisabilité. Ces mesures auraient pu être biaisées d'une manière ou d'une autre. En effet, notre environnement de test n'est pas soumis à une charge régulière de type production, mais est dédié à son seul objectif : l'estimation approximative !
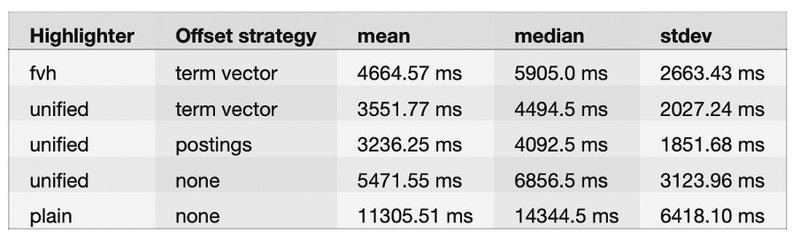
Notre test a utilisé la propriété de résultat "took" comme valeur représentative du nombre de millisecondes qu'il a fallu pour que la requête soit retournée. Nous avons effectué 100 recherches demandant une taille de 1000 documents sur trois index différents, chacun utilisant une stratégie de décalage différente.
Sans surprise, le surligneur simple sans stratégie de décalage est moins performant en raison de sa mise en œuvre technique. D'après notre ensemble de données, le surligneur unifié par défaut avec la stratégie de décalage des écritures semble être le plus efficace. En outre, il semble plus performant sur notre ensemble de données que le FVH avec la stratégie de décalage du vecteur de terme. Nous pensons que le vecteur de terme avec le FVH conviendrait mieux à des champs de texte plus grands comme indiqué dans la documentation officielle (> 1 MB).

Le terme vectoriel consomme évidemment le plus d'espace disque en raison de sa structure de données supplémentaire. Nous pouvons constater que les écritures augmentent l'utilisation du disque d'environ 20 %, ce qui, à notre avis, est encore abordable d'un point de vue commercial.
Si nous prenons en compte les performances et l'utilisation du disque, il ne fait aucun doute que les écritures avec un surligneur unifié sont un bon candidat pour notre implémentation.
Rechercher les données avec Kibana
Lorsque vous essayez d'interroger les données avec Kibana, le logiciel de tableau de bord de visualisation des données d'Elasticsearch, vous constatez qu'il est très lent. Le problème ne vient pas d'Elasticsearch mais de l'application frontale Kibana. En effet, Kibana essaie de charger tous les grands champs de texte deux fois dans la page.
Tout d'abord, le grand champ de texte fait partie du champ source_. Pour accélérer Kibana, vous n'avez pas d'autre choix que d'exclure le champ texte large de la source. Vous pouvez le faire dans la configuration du modèle d'index sous l'onglet Field filtering_ dans la version la plus récente d'Elasticsearch.
Deuxièmement, la partie en surbrillance du résultat de la requête contiendra le champ de texte complet et non des fragments. Un fragment n'est qu'une partie du texte contenant la valeur mise en évidence. Examinons la partie en surbrillance de la requête générée lors d'une recherche dans l'onglet "Découverte" :
"highlight": {
"pre_tags": [
"@kibana-highlighted-field@"
],
"post_tags": [
"@/kibana-highlighted-field@"
],
"fields": {
"*": {}
},
"fragment_size": 2147483647
}
La cause du problème est la taille du fragment qui est la valeur maximale d'un entier. Kibana demande le plus grand fragment de mise en évidence possible, ce qui entraîne le chargement de l'intégralité du champ de texte. Kibana agit ainsi car nous pensons qu'il n'est pas en mesure pour l'instant d'afficher plusieurs fragments de mise en évidence. Il n'y a pas d'autre choix pour remédier à cela que de désactiver la fonctionnalité de mise en évidence dans les paramètres avancés de Kibana.
Conclusion
Nous avons découvert que Kibana ne fonctionne pas avec des champs de texte de grande taille, en particulier pour la fonction de mise en évidence. Si nous voulons faire le lien avec l'article précédent de la partie 1, il sera logique de ne pas stocker de texte de grande taille pour économiser de l'espace disque par un facteur potentiel de 2. Nous croyons fermement qu'une application frontale dédiée est fortement nécessaire pour mettre en œuvre la mise en évidence avec des champs de texte de grande taille pour l'instant dans nos cas d'utilisation particuliers.